Visibilidade em IA: Redefina Sua Medição para Impacto Estratégico Real
A forma como as empresas medem sua visibilidade em sistemas de Inteligência Artificial está sendo reinventada. A abordagem tradicional, baseada em prompts genéricos, falhava em capturar a complexidade do comportamento do usuário. Agora, uma nova metodologia surge para oferecer dados mais precisos e acionáveis, focando no contexto real do usuário para otimizar estratégias de SEO e marketing digital.
Atualizado em 25 de junho de 2024 • Leitura estimada: 8-10 min
Resumo rápido
- A medição convencional da visibilidade em IA falha por usar prompts genéricos que ignoram o contexto real do usuário, gerando dados pouco práticos.
- O framework SPIV (Segmento, Persona, Intenção, Variável) transforma inputs de IA sem contexto em proxies de alta fidelidade para o comportamento do usuário.
- Essa metodologia inovadora introduz camadas de métricas secundárias que revelam a estabilidade e a dinâmica competitiva, conectando diretamente a visibilidade a prioridades de negócio tangíveis.
O que aconteceu
A forma predominante de rastrear a visibilidade em ambientes de Inteligência Artificial, até então, baseava-se em premissas equivocadas. A maioria das auditorias de visibilidade em IA utilizava prompts amplos e pouco específicos, buscando medir usuários hipotéticos com ferramentas determinísticas em um sistema que é inerentemente probabilístico. Esse método, embora intuitivo, gerava dados que, apesar de parecerem relevantes, não espelhavam o comportamento real do comprador, resultando em informações superficiais e de difícil aplicação prática.
Somado a isso, as auditorias iniciais de visibilidade em IA frequentemente mimetizavam o formato das auditorias tradicionais de SEO. Um único documento tentava abarcar excesso de informações, como auditoria de conteúdo, análise de concorrentes, revisão de dados estruturados e recomendações estratégicas. Essa densidade de dados, contudo, acabava por confundir os clientes, que não conseguiam extrair ações claras e prioritárias, exigindo múltiplas sessões para decifrar o que fazer primeiro. O problema não era apenas a medição falha, mas também a apresentação da informação, que ofuscava o sinal em meio a muito ruído.
Ponto-chave
A visibilidade em IA não é um número estático de ranqueamento, mas uma distribuição de probabilidade que reflete quão confiavelmente uma marca aparece quando as condições contextuais e a intenção real do usuário são consideradas.
Por que isso importa
A transição para uma metodologia mais refinada na medição de visibilidade em IA é crucial porque ela transforma dados de meramente ‘interessantes’ para ‘úteis’. Ao analisar os impactos da notícia no mercado, nas empresas, nos consumidores e nas tendências digitais, a nova abordagem revela consequências práticas, oportunidades inexploradas, riscos ocultos e mudanças significativas. Em vez de apenas saber ‘onde estamos’, entendemos ‘por que estamos lá’ e ‘o que podemos fazer a respeito’.
O leitor deve prestar atenção a este assunto porque ele redefine a competitividade no cenário digital. Conecta-se diretamente com o comportamento de consumo na era da IA, acelera a transformação digital, impulsiona a inovação em marketing e tecnologia, e otimiza a gestão estratégica. Esta nova forma de medir a visibilidade em IA capacita as empresas a tomar decisões de conteúdo e investimento em PR mais assertivas e defensáveis, alinhadas com o que realmente importa para seus compradores.
Impactos práticos
Para empresas
Empresas podem direcionar seus investimentos em conteúdo e relações públicas de forma mais eficiente. Ao identificar lacunas de visibilidade em tópicos de alta intenção e em plataformas específicas, elas podem criar estratégias de SEO para IA que respondam diretamente às necessidades de seus compradores, aumentando a probabilidade de serem mencionadas por modelos de IA nos momentos cruciais da jornada de decisão.
Para consumidores
O público final se beneficia de respostas mais relevantes e contextualizadas dos modelos de IA. Com empresas otimizando seu conteúdo para perfis e intenções de busca mais específicas, a experiência do usuário melhora, fornecendo informações precisas e úteis exatamente quando necessário, seja para pesquisa, comparação ou tomada de decisão.
Para o mercado
O mercado como um todo se move de uma abordagem focada em volume para uma busca por respostas de alta qualidade e contextualizadas. Isso altera a dinâmica competitiva, tornando tópicos com baixa entropia (dominados por poucos players) mais desafiadores, enquanto tópicos de alta entropia (resultados fragmentados) se tornam oportunidades valiosas para novas entradas e consolidação de autoridade.
O que aconteceu
A primeira postagem desta série argumentou que a maioria do rastreamento de visibilidade em IA está construída sobre uma base incorreta: prompts genéricos que medem usuários hipotéticos e ferramentas determinísticas aplicadas a um sistema probabilístico. Se esse diagnóstico estiver correto, a próxima pergunta óbvia é: como uma abordagem melhor realmente se parece?
Isso é o que esta postagem aborda. O que construímos na NP Digital para resolver tanto o problema de medição quanto um segundo problema que o agravava: as auditorias iniciais de visibilidade em IA estavam tentando fazer muitas coisas ao mesmo tempo, produzindo resultados tão densos que os clientes não conseguiam identificar uma única ação clara para tomar. A reconstrução abordou ambos os problemas juntos.
O resultado é uma metodologia construída em torno da construção estruturada de prompts, duas camadas de métricas e saídas que apontam para ações específicas e defensáveis. Veja como funciona.
Por que a Antiga Abordagem de Auditoria Não Funcionava
Antes de explicar o que construímos, ajuda explicar do que estávamos nos afastando e por quê.
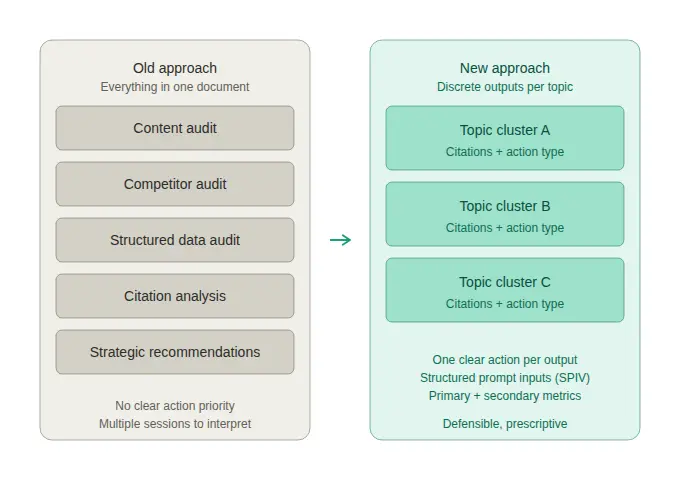
As auditorias iniciais de visibilidade em IA, incluindo nossas próprias tentativas iniciais, eram estruturadas como auditorias de SEO. Um único documento tentava cobrir tudo de uma vez: uma auditoria de conteúdo, uma auditoria de concorrentes, uma revisão de dados estruturados, análise de citações e recomendações estratégicas, tudo agrupado em uma única saída. A lógica fazia sentido na época. As auditorias de SEO sempre funcionaram assim. Por que uma auditoria de GEO seria diferente?
A resposta, na prática, era que os clientes não conseguiam usá-las. Os pontos de dados entravam em conflito. A direção estratégica não estava clara. O mesmo documento tinha que ser reapresentado várias vezes antes que alguém pudesse concordar sobre o que fazer primeiro. Estávamos produzindo um trabalho completo que deixava os clientes mais confusos do que quando começaram.
Dois problemas estavam correndo em paralelo. O primeiro foi o problema de medição que abordei anteriormente: prompts genéricos produzindo dados que pareciam significativos, mas não eram representativos do comportamento real do comprador. O segundo foi um problema de apresentação: mesmo que os dados tivessem sido melhores, o formato enterrava o sinal em muito ruído.
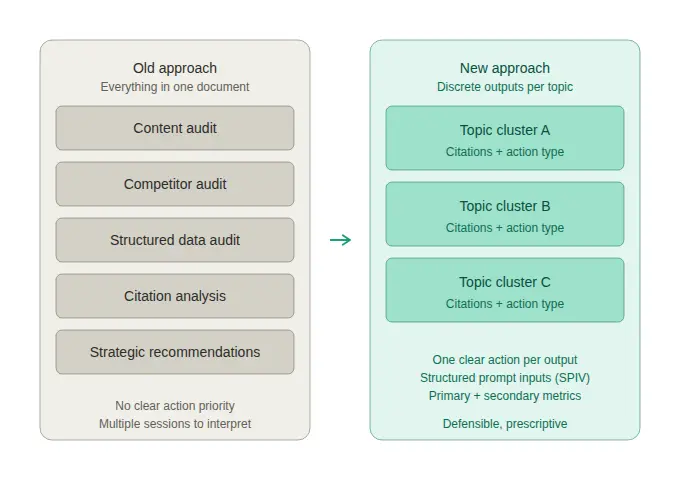
A reconstrução abordou ambos. No lado da medição, passamos para a construção estruturada de prompts através do framework SPIV. No lado da saída, separamos a análise em peças discretas e digeríveis: cada uma focada em um cluster de tópicos específico, cada uma apontando para um tipo de ação definido. Os clientes pararam de precisar de várias sessões para entender o que estavam vendo.
Apresentando o Framework SPIV
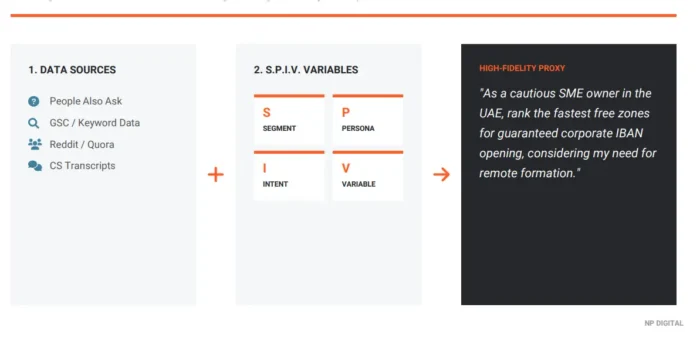
O ponto de partida são dados familiares. As mesmas fontes que alimentam a pesquisa tradicional de palavras-chave, incluindo resultados de “Pessoas Também Perguntam”, dados do Google Search Console, plataformas da comunidade como Reddit e Quora, e dados próprios, como transcrições de atendimento ao cliente, quando disponíveis, fornecem a matéria-prima. A diferença é o que acontece em seguida.
Em vez de usar esses inputs como estão, o SPIV os trata como matéria-prima e injeta quatro variáveis estruturadas em cada prompt. O efeito prático: ele transforma inputs de pesquisa de palavras-chave de IA sem estado em respostas pseudo-estado, dando ao modelo o contexto da persona que ele, de outra forma, estaria perdendo.
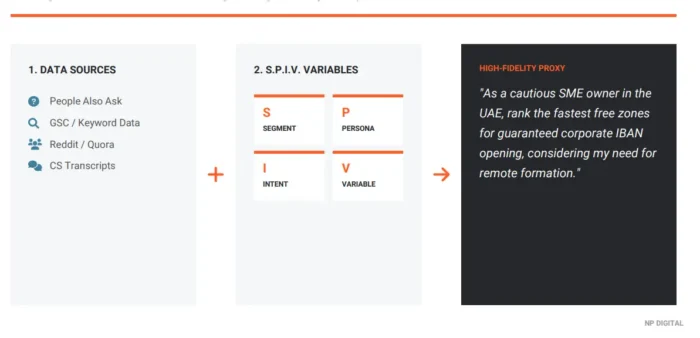
Cada variável desempenha uma função específica:
- Segmento: A categoria de mercado ou contexto de negócio. Baseia o prompt em uma situação definida: ‘Dono de PME nos Emirados Árabes Unidos’ em vez de ‘dono de negócio’. Esta é a camada mais ampla de contexto.
- Persona: O tipo de usuário específico, incluindo traços relevantes: tolerância a riscos, nível de conhecimento prévio, contexto geográfico ou profissional. É aqui que ‘usuários’ abstratos se tornam pessoas reais com restrições reais.
- Intenção: O que o usuário está realmente tentando realizar, não o tópico que está pesquisando, mas o resultado que precisa. ‘Entender minhas obrigações de conformidade’ é diferente de ‘encontrar a opção mais barata’. Separar estes pontos revela diferenças significativas na forma como os modelos respondem.
- Variável: Um único modificador que pode ser alterado para testar a sensibilidade: ‘o mais rápido’ vs. ‘o mais barato’ vs. ‘o mais confiável’. Isolar uma variável por vez torna os dados interpretáveis. Mude tudo e você não conseguirá explicar o que mudou.
A tabela abaixo mostra como essa transformação se parece na prática, usando exemplos anônimos de trabalho de auditoria real:

A diferença entre o input bruto e o prompt otimizado pelo SPIV não é cosmética. O prompt bruto não descreve ninguém em particular. O prompt otimizado descreve uma pessoa específica em uma situação específica tentando alcançar um resultado específico. Essa especificidade é o que torna a resposta do modelo significativa como um input de medição.
Um conjunto bem construído de prompts SPIV não precisa ser grande. A representatividade importa mais do que o volume. Um conjunto focado de 15 a 30 prompts mapeados para suas principais personas de comprador e estágios de intenção fornece um sinal mais acionável do que centenas de variações genéricas.
As Duas Camadas de Medição: Métricas Primárias e Secundárias
Uma vez que os prompts são devidamente construídos, a análise opera em duas camadas distintas. Compreender a diferença entre elas é o que torna o resultado útil, em vez de apenas interessante.
Métricas primárias vêm diretamente das plataformas de rastreamento, incluindo Writesonic e Profound. Estas incluem porcentagem de visibilidade, share of voice e frequência de menção. São as saídas padrão com as quais a maioria das equipes já está familiarizada e fornecem o panorama básico: com que frequência sua marca aparece e como isso se compara aos concorrentes?
As quatro métricas secundárias e o que cada uma delas informa:
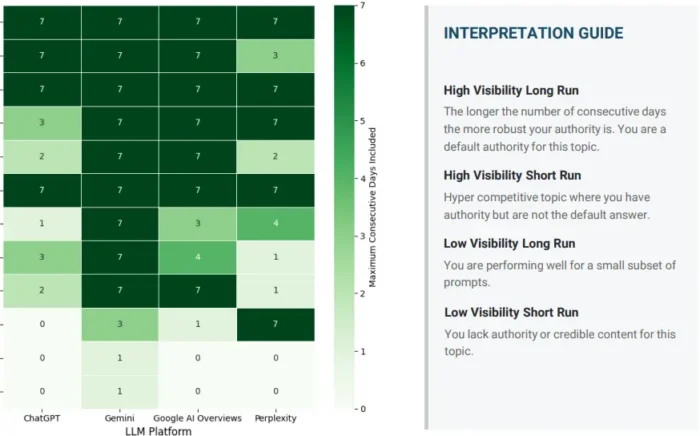
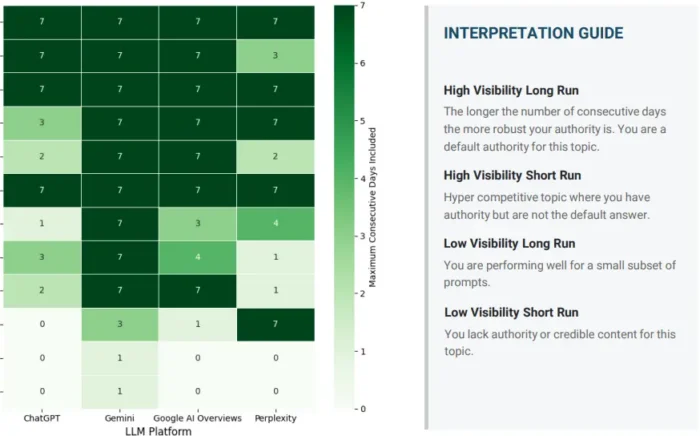
- Duração da sequência (Run length): O número de dias consecutivos que uma marca mantém a visibilidade para um determinado tópico. Sequências curtas sinalizam presença volátil e não confiável. Sequências longas indicam que o modelo formou uma associação estável entre a marca e esse tópico, o que chamaríamos de autoridade persistente em vez de uma menção transitória.
- Entropia de Shannon: Uma medida de quão uniformemente a visibilidade é distribuída entre as marcas que aparecem para um determinado tópico. Alta entropia significa que nenhuma marca domina, o que significa que o modelo está puxando de um campo amplo e fragmentado. Baixa entropia significa que os resultados estão concentrados e que um pequeno número de marcas está recebendo a maioria das menções. Tópicos de baixa entropia são mais difíceis de penetrar; tópicos de alta entropia são mais contestáveis.
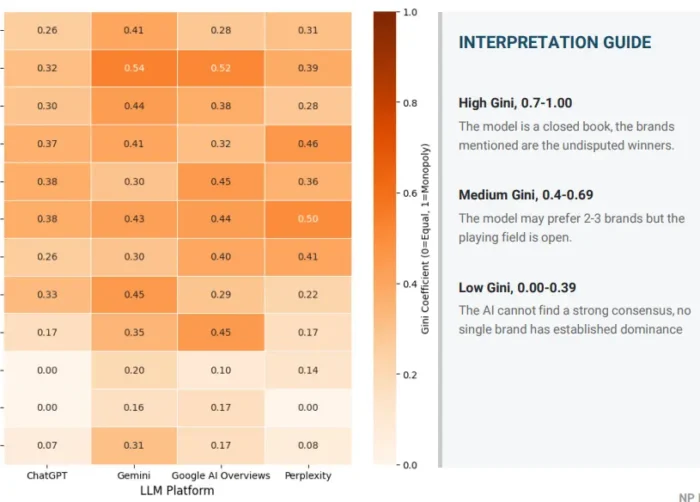
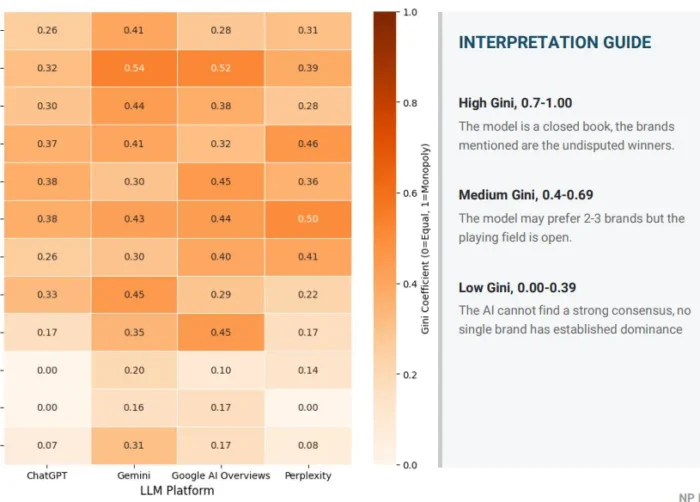
- Coeficiente de Gini: Onde a entropia de Shannon informa como os resultados são distribuídos, o coeficiente de Gini informa o grau de concentração. Uma pontuação Gini alta significa que a visibilidade é dominada por uma ou duas marcas. Uma pontuação baixa significa que o campo é relativamente aberto. Juntamente com a entropia, isso dá uma imagem de se um tópico é “o vencedor leva a maior parte” ou genuinamente compartilhado.
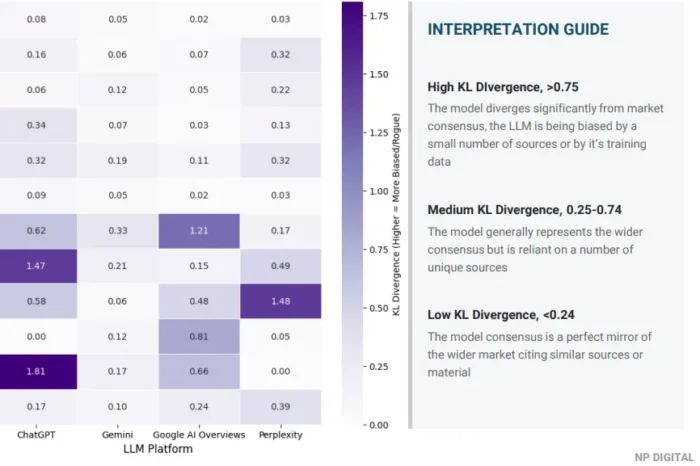
- Divergência KL: Em um contexto estatístico tradicional, essa métrica mede como uma distribuição muda ao longo do tempo. Adaptamos aqui para servir a um propósito diferente: medir o quão longe os resultados de uma plataforma individual se desviam da média do grupo em todas as plataformas rastreadas. Uma pontuação baixa para uma determinada plataforma significa que seus rankings de marca para esse tópico estão amplamente alinhados com o consenso entre ChatGPT, Gemini e Perplexity. Uma pontuação alta significa que a plataforma está escolhendo um conjunto significativamente diferente de marcas. Essa é uma descoberta significativa. Ela informa se sua visibilidade é genuinamente ampla ou se está concentrada na visão de mundo de um único modelo.
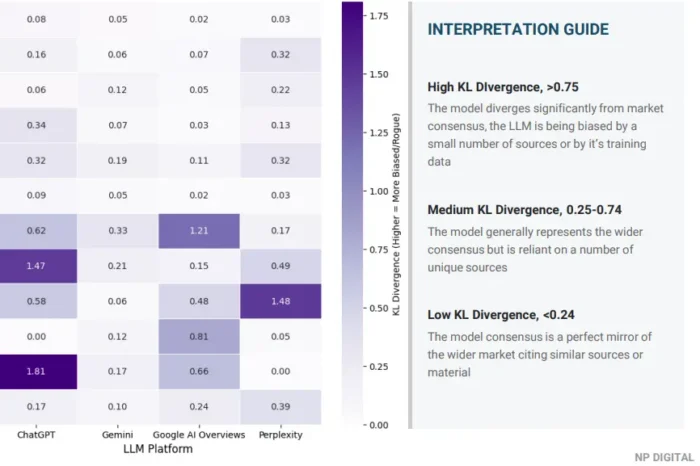
Nenhuma dessas métricas é útil isoladamente. A duração da sequência informa o quão estável é sua visibilidade; a entropia e o Gini informam o quão competitivo é o tópico; a divergência KL informa se essa visibilidade se mantém em todas as plataformas ou se é frágil de uma forma que seus números principais não revelam. Lidas em conjunto, elas fornecem um quadro diagnóstico que as métricas primárias sozinhas não podem produzir.
O que os Dados Revelam
Com prompts estruturados pelo SPIV e ambas as camadas de métricas implementadas, a visibilidade deixa de ser um número único e se torna uma distribuição de probabilidade. A questão muda de ‘onde ranqueamos?’ para ‘quão confiavelmente aparecemos quando as condições que realmente importam estão presentes?’
Na prática, essa abordagem revela descobertas em três dimensões que o rastreamento genérico perde completamente.
A própria distribuição da visibilidade. Algumas marcas são pilares da categoria: elas aparecem consistentemente em múltiplas execuções do mesmo prompt, em pequenas variações de fraseado, em diferentes plataformas. Outras são outliers voláteis: elas surgem ocasionalmente, mas não podem ser confiadas. O rastreamento genérico faz uma média disso e produz uma figura principal que obscurece a diferença. As métricas secundárias separam os dois claramente.

A dimensão da plataforma. Visibilidade que se mantém no Google Gemini, mas não no ChatGPT, é uma descoberta significativa, não apenas um ponto de dados a ser descartado. Diferentes modelos baseiam-se em diferentes dados de treinamento, ponderam diferentes tipos de fonte e respondem de forma diferente à mesma intenção subjacente. A divergência KL torna isso visível. Uma marca que parece forte no agregado, mas tem uma pontuação de alta divergência em uma plataforma, tem um risco de concentração que importa estrategicamente, especialmente se essa plataforma é onde seus compradores realmente pesquisam.
A dimensão do tópico. Esta é frequentemente a descoberta mais estrategicamente importante em toda a auditoria. As marcas regularmente mostram forte visibilidade em consultas amplas e de baixa intenção (os termos de categoria geral que aparecem bem no rastreamento padrão), mas presença quase nula nos tópicos específicos e de alta intenção que seus compradores estão pesquisando no momento da decisão.
Em uma auditoria, uma marca mostrou visibilidade acima de 65% para tópicos gerais de licenciamento em todas as plataformas. Para tópicos de conformidade e bancários (as duas áreas mais diretamente conectadas ao processo de tomada de decisão de seus compradores), a visibilidade era zero em ChatGPT, Google AI Overviews e Perplexity. O rastreamento padrão parecia saudável. O quadro real era que a marca estava invisível nos momentos que mais importavam.
Prompts genéricos perdem isso porque não estão fazendo as perguntas certas. Prompts estruturados pelo SPIV revelam isso porque são construídos em torno dos contextos onde as decisões realmente acontecem.
É aqui também que a medição se conecta diretamente à estratégia de SEO para IA. Uma vez que você sabe quais tópicos mostram lacunas, quais plataformas são mais divergentes e quais concorrentes estão mantendo as posições que você não tem, você tem um briefing defensável para investimento em conteúdo e PR. A auditoria não apenas informa onde você está. Ela informa para onde ir.
FAQs
Como você rastreia a visibilidade em IA?
O rastreamento da visibilidade em IA começa com um conjunto de prompts definidos executados nas principais plataformas: ChatGPT, Google Gemini, Perplexity e Google AI Overviews. Ferramentas como Writesonic e Profound automatizam esse processo e exportam dados de visibilidade por marca e tópico. O passo crítico que a maioria das equipes pula é estruturar esses prompts em torno de personas de comprador reais e contextos de intenção, em vez de termos genéricos de categoria. Prompts genéricos produzem dados direcionais; prompts estruturados produzem dados nos quais você pode agir.
Como você monitora a visibilidade da marca em IA?
A visibilidade da marca em IA é monitorada executando prompts estruturados em plataformas de forma recorrente e rastreando métricas primárias (porcentagem de visibilidade, share of voice) e secundárias (duração da sequência, entropia, coeficiente de Gini, divergência KL). As métricas primárias informam quais são os números. As métricas secundárias informam se esses números são estáveis, quão competitivo é o tópico e se sua visibilidade é genuinamente ampla ou concentrada em uma única plataforma. Monitorar ambas as camadas fornece um quadro sobre o qual você pode agir.
Como verifico a visibilidade da minha marca em IA?
Comece identificando os tópicos mais relevantes para o processo de tomada de decisão de seus compradores, não apenas os termos de categoria amplos, mas as perguntas específicas que eles fazem quando estão próximos de uma compra. Crie prompts em torno desses tópicos usando o framework SPIV, execute-os em ChatGPT, Gemini, Perplexity e Google AI Overviews, e rastreie a consistência com que sua marca aparece. A lacuna entre sua visibilidade em tópicos gerais e sua visibilidade em tópicos de alta intenção e estágio de decisão é geralmente a descoberta mais importante.
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “How do you track AI visibility?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “
Tracking AI visibility starts with a defined prompt set run across the major platforms: ChatGPT, Google Gemini, Perplexity, and Google AI Overviews. Tools like Writesonic and Profound automate this process and export visibility data by brand and topic. The critical step most teams skip is structuring those prompts around real buyer personas and intent contexts rather than generic category terms. Generic prompts produce directional data; structured prompts produce data you can act on.
”
}
}
, {
“@type”: “Question”,
“name”: “How do you monitor brand visibility in AI?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “
Brand visibility in AI is monitored by running structured prompts across platforms on a recurring basis and tracking both primary metrics (visibility percentage, share of voice) and secondary metrics (run length, entropy, Gini coefficient, KL divergence). The primary metrics tell you what the numbers are. The secondary metrics tell you whether those numbers are stable, how competitive the topic is, and whether your visibility is genuinely broad or concentrated on a single platform. Monitoring both layers gives you a picture you can act on.
”
}
}
, {
“@type”: “Question”,
“name”: “How do I check AI visibility of my brand?”, “acceptedAnswer”: {
“@type”: “Answer”,
“text”: “
Start by identifying the topics most relevant to your buyers’ decision-making process, not just the broad category terms, but the specific questions they ask when they’re close to a purchase. Build prompts around those topics using the SPIV framework, run them across ChatGPT, Gemini, Perplexity, and Google AI Overviews, and track how consistently your brand appears. The gap between your visibility in general topics and your visibility in high-intent, decision-stage topics is usually the most important finding.
”
}
}
]
}
Conclusão
A mudança que esta metodologia proporciona é simples de declarar, mas significativa na prática: você não está mais rastreando onde ranqueia. Você está rastreando quão confiavelmente você aparece quando realmente importa: para a persona certa, no estágio de intenção correto, nas plataformas que seus compradores realmente usam.
O SPIV é como você constrói os inputs que tornam essa medição possível. As métricas secundárias são como você entende o que os dados estão dizendo. Juntos, eles transformam a visibilidade da IA de um número principal em um diagnóstico que aponta para algo útil.
Saber onde você é visível e onde não é é apenas metade da equação. Na postagem final desta série, abordarei o que este framework revela sobre a estratégia de conteúdo e por que a antiga abordagem de volume primeiro não se sustenta em um ambiente de busca orientado por respostas.



Fonte: Neil Patel